

The Opsgenie incident management platform centralises and organises alerts, reliably notifies the appropriate people, and enables them to effectively communicate and take rapid action throughout an incident’s lifecycle.
Opsgenie supports native integrations for over 200 applications, including Jira Software and Jira Service Desk. For other applications, Opsgenie Integrations are made possible by utilising Opsgenie’s REST APIs or Email API.
Alert and on-call management tools are highly customisable within Opsgenie and facilitate granular control of notification preferences for services, teams and individual users. These features make Opsgenie particularly desirable as they can prevent downtime caused by overlooking major alerts, whilst stopping teams from getting distracted by being overloaded with low-priority alerts.
Core Features of Opsgenie Integration
Roles
Opsgenie defines two user structures – Responders and Stakeholders. Responders can view and receive notifications, act on Alerts/Incidents and make Opsgenie configurations. Stakeholder Users can only be notified about ongoing Incidents and follow their status.
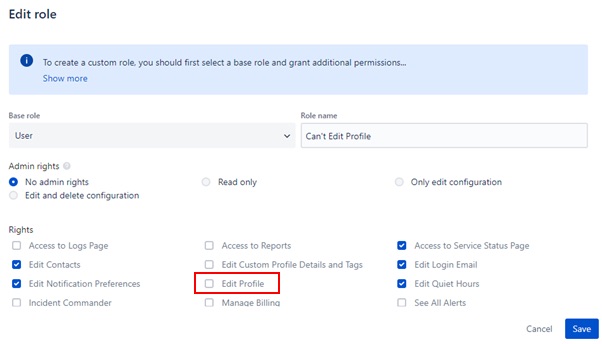
Roles can be further refined on a Global or Team level (e.g. Admin, Team Leader) to give different users different levels of configuration, and Custom Roles can be created using a default user type as a base role and configuring permissions accordingly.
User Notification Customisation
Each user can edit their own profile and thereby configure their own notification preferences. This involves selecting their preferred contact methods (email, SMS etc.) and directing different types of Alerts to these contact methods by creating rules.
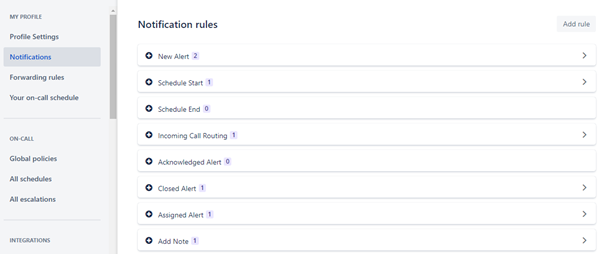
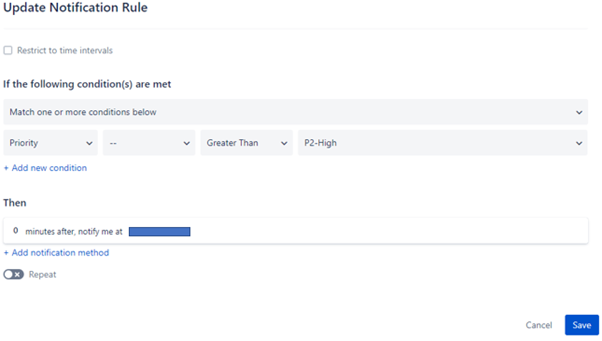
In certain cases, it may not be desirable for Users to be able to alter their own preferences. To facilitate this, users should be assigned a Custom User Role with the “Edit Profile” permission disabled.
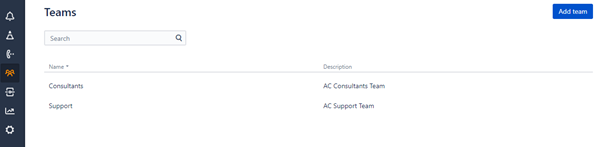
Teams
Teams are a way to represent organisational structure in Opsgenie. Users can be part of multiple Teams and are assigned a Role within each Team. The Opsgenie features discussed in the following sections are configured specific to each Team. This means that, for example, each Integration with Jira Software must be configured separately for each Team. A single Team can even have multiple Integrations with the same application, which are also configured separately (e.g. multiple Integrations with Jira Service Desk, each linked to a different Jira project).
Escalations & Schedules
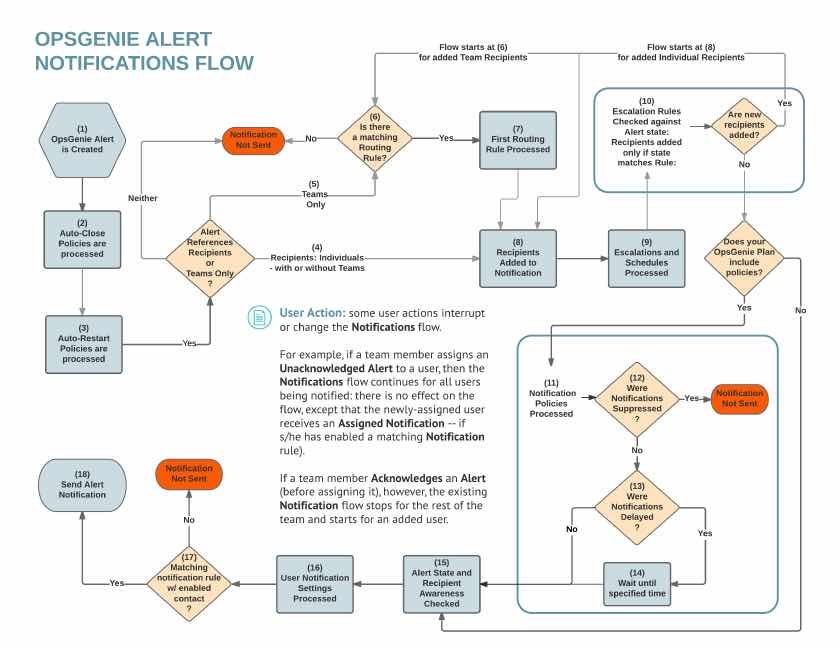
A key feature of Opsgenie is configuring how each Team receives Alerts. This is done using four key components: On-call Schedules, Escalations, Routing Rules and Team (or Global) Policies.
1. On-call Schedules
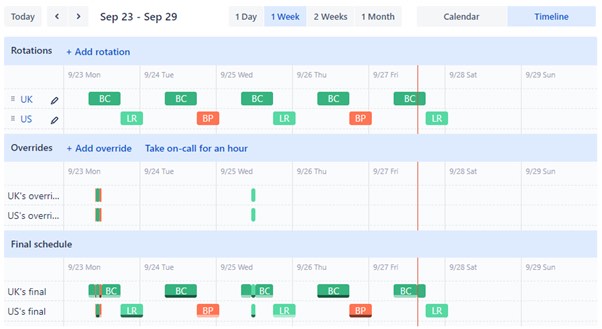
An On-call Schedule defines which Team member to route Alerts to depending on the date and time. Each Team can have multiple Schedules, each with custom Rotations (e.g. primary and backup, US and UK), which determine which Team member is currently on-call (on-call users will usually be the first point of contact for most Alerts). Rotations can include one or multiple users and can be configured on a Monthly, Weekly, Daily or Custom basis (e.g. weekdays only).
An Override take precedence over the Schedule, and enables manual selection of a Team member to be placed on-call. Overrides can be executed at any time (e.g. due to illness) and the final Schedule will be updated automatically to account for these.
Users can choose if/how they wish to be notified about the start of an upcoming rotation within their Profile Settings, where they can also view their personal On-call Schedules across all the Teams of which they are a member.
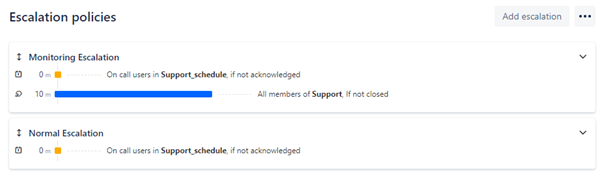
2. Escalation Policies
Escalation Policies describe the series of notifications that occur when the team does not acknowledge or close an Alert within specified time frames. For example, a Policy may state that an Alert initially notifies only the Team member(s) that are on-call, however if the Alert is not closed after 10 minutes, the entire Team is notified.
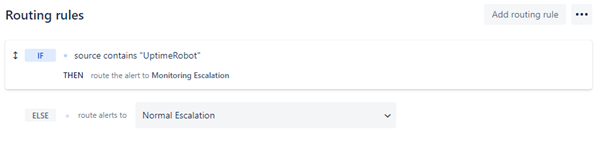
3. Routing Rules
Routing Rules direct incoming Alerts to the appropriate Escalation Policy. Rules can be based on, for example, an incoming Alert’s Source or Priority.
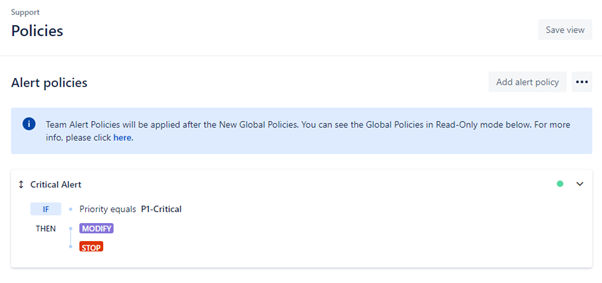
Policies
Alert Policies can be configured on either a Global or Team level (Global Policies will be prioritised). Policies can either match all incoming Alerts or apply only to certain Alerts based on a filter e.g. Alerts created from a specific Source or of a given Priority. If the Alert fulfils the filter conditions, the Policy can then define the Alert’s fields (Message, Priority, Description etc.) as well as assign Responders to the Alert (a Team, specific Users or a combination of the two).
In addition to Alert Policies, Teams can configure Notification Policies, which allow them to Auto-Restart (discard and restart the notification flow after a specified time), Auto-Close (closing an Alert after a specified time) and Delay/Suppress Alerts. The last of these can be particularly useful for Duplicate Alerts.
Each Alert in Opsgenie is given an unique ID (Alias) and no two open Alerts with the same Alias can simultaneously exist in Opsgenie. Hence, if an identical Alert is received multiple times, a new Alert will not be created – instead, the Alert Count will increase. Duplicate Alerts can be delayed until their count reaches a specified number or the Alert occurs a given number of times within a given time period.
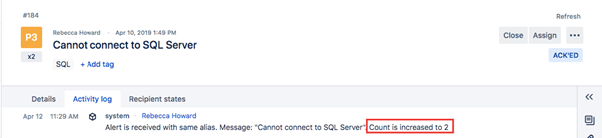
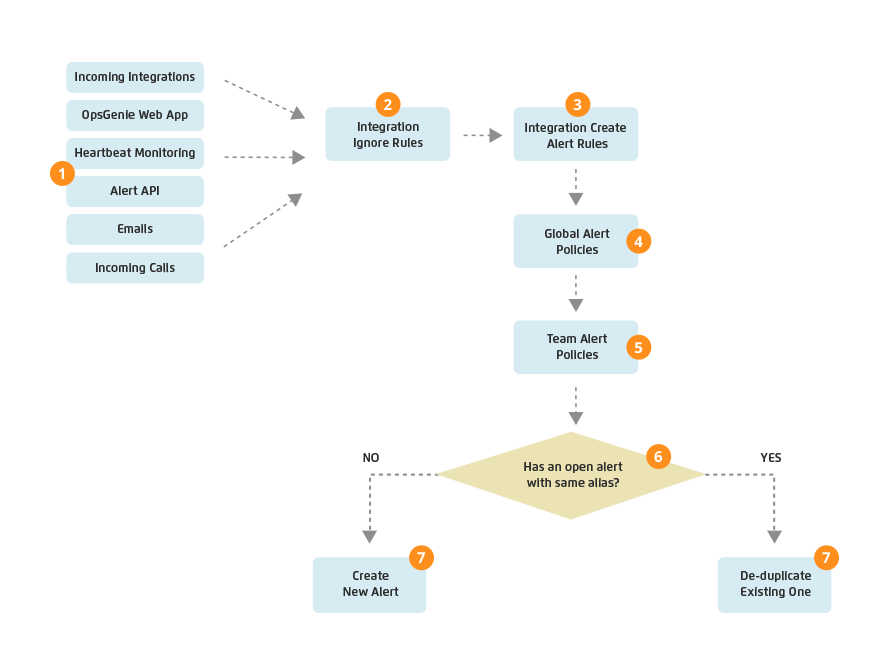
What is important to note, is that incoming Alerts will only execute the first Policy that they match (where order matters) unless Continue To Next Policy is enabled on that particular Policy. If Continue To Next Policy is enabled, the next policy is processed in alert policy list. This chain execution stops at the first policy which has disabled this option. The schematic below illustrates how Opsgenie deals with incoming Alerts.
Integrations
Opsgenie supports over 200 native integrations. As with the previous features, integrations are configured specific to each Team. Within each Integration’s configuration, Opsgenie provides a comprehensive step-by-step guide of how to set up the integration. Jira is a leading issue tracking tool, also owned by Atlassian, and will serve to demonstrate how an integration can be set up with Opsgenie.
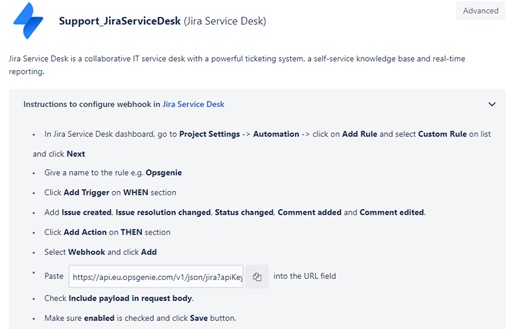
Teams can configure how Opsgenie Alerts interact with Issues in Jira Software/Jira Service Desk. Jira Issues can be created from Opsgenie Alerts and vice versa. Rules can be defined to map Alert actions with Issue actions and filter which Alerts and Issues these actions apply to. They also direct Opsgenie to the relevant Jira Project.
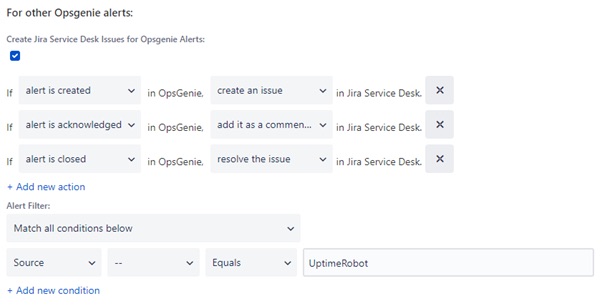
Other native Integrations can be set up in a similar manner.
Opsgenie’s Email API and REST APIs can be utilised for applications that currently are not including in the 200 native integrations. For example, an external application can configure a mail handler to direct emails to an Opsgenie Team’s email address, which Opsgenie generates after setting up the Email API integration. A Team can also have multiple email addresses simply by configuring multiple Email API integrations.
Example – Jira Service Desk with a monitoring application
In the example below, a Team have configured an Integration with Jira Service Desk to create Issues in a Jira Project when an external service they are monitoring registers downtime.
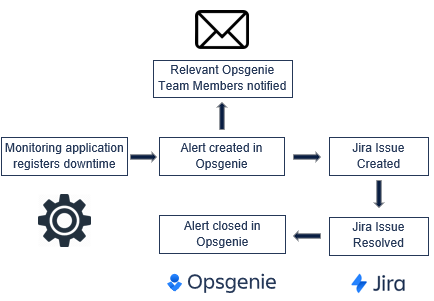
Opsgenie creates an Alert after being notified by the monitoring application. Opsgenie then sends a notification to the relevant Team member(s) based on the aforementioned Routing Rules and Escalation Policies. An Issue is then created in the designated Jira Project by the Jira Service Desk integration. When the issue is resolved in Jira, the Alert is closed in Opsgenie. It is worth noting that the Integration with the monitoring application could be configured to automatically close the Opsgenie Alert (and Jira Issue) when the monitored service becomes active again.
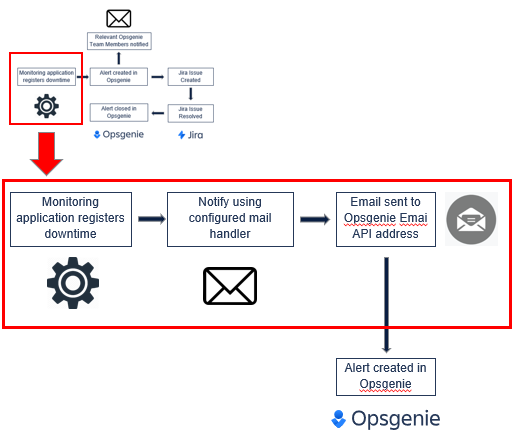
This scenario can be extended to demonstrate what would occur if the monitoring application did not have a native Integration with Opsgenie. The monitoring application would require the additional step of configuring a mail handler to send notifications to the Team’s email address defined within the Email API Integration.
Services
An Opsgenie Service provides a single source of truth for services that are of business interest. It facilitates Incident Management for given service outages or disruptions. Services can be either Internal (e.g. Login Service) or External (public statuspages e.g. Jira’s statuspage).
Opsgenie Services are an effective way to quickly communicate and respond to Incidents and to notify and update relevant Stakeholders and Subscribers (Opsgenie Users can Subscribe to a Service to receive notifications, as long as the Service is configured to be public to the organisation). Each Service (Internal or External) requires an Owner Team – members of this Team are also automatically added as Responders to all Incidents attributed to the Service. Additional Responders (Teams or Individuals) can also be assigned in the Service configuration, or for individual Incidents (likewise for Stakeholders). Templates for Stakeholder email notifications can also be created.
Incidents can be created both manually (by Admin Users of the Owner Team) or automatically from Alerts, which is configured using Incident Rules.
The Problem Reporting feature allows Users to quickly report issues related to a Service by entering a Description and Severity Level. An Administrator can configure the mapping between the Severity Levels of a reported Problem and the Priority of the corresponding Alert created. Problems can be upvoted by other users to increase their count – a rule can then be created to escalate recurring problems to a higher Priority level.
For example, Problem Reporting can be configured so that an Alert created from a Problem can never have Critical Priority (instead map to High Priority), however if any problem is reported 3 times then its priority is automatically set to Critical.
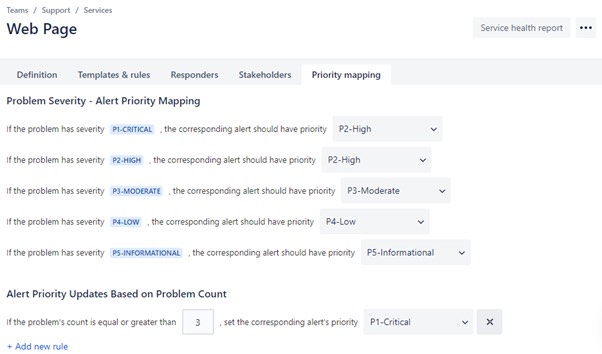
The example above (and displayed in the screenshot) could then be extended by defining an Incident Rule to create Incidents from all Alerts originating from the Service which has a critical Priority. Putting this all together would mean an Incident would be automatically generated for the Service if the same Problem is experienced by at least 3 Users.
Services support rapid and easy communication between Responders through:
- Displaying a Timeline of key events within the Incident
- Conferences – an Opsgenie feature which facilitates video and audio calls
- Assigning Incident Response Roles: Incident Commander, Communications Officer, Scribe, Subject Matter Expert – these are the default Roles and can be customised.
Upon resolving an Incident, Postmortems are created in order to allow Teams to learn from Incident history and improve future practice. A User resolving an Incident must fill in details regarding the Incident including detection, causes, mitigation, resolution. A draft of the Postmortem is then reviewed and after it is published, data on Incident duration, time to respond etc. is automatically generated and attached to the Postmortem.
Heartbeats
Heartbeats are used to monitor connectivity between Opsgenie and other systems – they can be used to monitor: tasks, job completion and system availability. Each system needs to send a Heartbeat request to Opsgenie and, again, each Heartbeat is specific to a Team.
Each system will send HTTP-based Heartbeats periodically – the period is customisable with up to one request per minute. If the Heartbeat in Opsgenie fails to receive a request within the specified time period, an Alert will be created.
Actions
Responders often take predictable, repetitive actions when responding to an Alert. Examples of these may include: gathering more info about a particular system, running network diagnostics, increasing cloud resources, or restarting a service. Opsgenie can be used to define such Actions with customisable parameters and be configured to trigger the Actions to be executed automatically. This can result in significant savings on a Responder’s time and reduce the number of applications they need to use.
Opsgenie currently supports 3 methods of performing such Actions:
- AWS Systems Manager
- Generic REST Endpoint
- AWS Simple Notification Service
Analytics & Reporting
In addition to Incident Postmortems, Opsgenie’s Analytics feature gives Users access to a range of reports and statistics on a Global, Team and User level. This includes data on Mean Time to Acknowledge/Respond to Alerts (MTTA/MTTR), types of Alert, User Activity, as well as weekly and monthly summaries (which are generated automatically and can be sent to Users via email).
Opsgenie Pricing Plans
The final topic that will be covered in this post is Opsgenie licensing. Opsgenie offers four plans: Free, Essentials, Standard and Enterprise. An owner of an Opsgenie instance can select which features they require and automatically be directed to the appropriate plan, however features can be added/removed after the instance has been created. All Users require a license but only Responder User licenses are chargeable – Stakeholder licenses are free of charge. For further information, see Opsgenie’s pricing information. here
Thank for you for taking the time to read this blog post. If you would like to find out more, or would be interested in a demonstration, please get in touch with Automation Consultants.



